
I am a Ph.D. student in Economics at Harvard, where I am supported by the National Science Foundation, the Center for Applied Artificial Intelligence, Two Sigma, and Opportunity Insights.
I completed my S.M. in Applied Mathematics and A.B. in Computer Science—summa cum laude, with certificates in Mind/Brain/Behavior and Global Health & Health Policy—at Harvard in 2019. I also spent time at Microsoft and Google.
Research
Working Papers
Lookahead Bias in Pretrained Language Models [Preprint]
with Keyon Vafa
Abstract
Empirical analysis that uses outputs from pretrained language models can be subject to a new form of temporal lookahead bias. This bias arises when a language model’s pretraining data contains information about the future, which then leaks into analysis that should only use information from the past. Lookahead bias is a form of information leakage that can lead otherwise-standard empirical strategies that use language model outputs to overestimate predictive performance. In this paper we develop tests for lookahead bias, based on the assumption that some events are unpredictable given a prespecified information set. Using these tests, we find evidence of lookahead bias in two applications of language models to social science: Predicting risk factors from corporate earnings calls and predicting election winners from candidate biographies. We additionally find issues with existing, ad hoc approaches to counteract this bias. The issues we raise can be addressed by using models whose pretraining data is free of survivorship bias and contains only language produced prior to the analysis period of interest.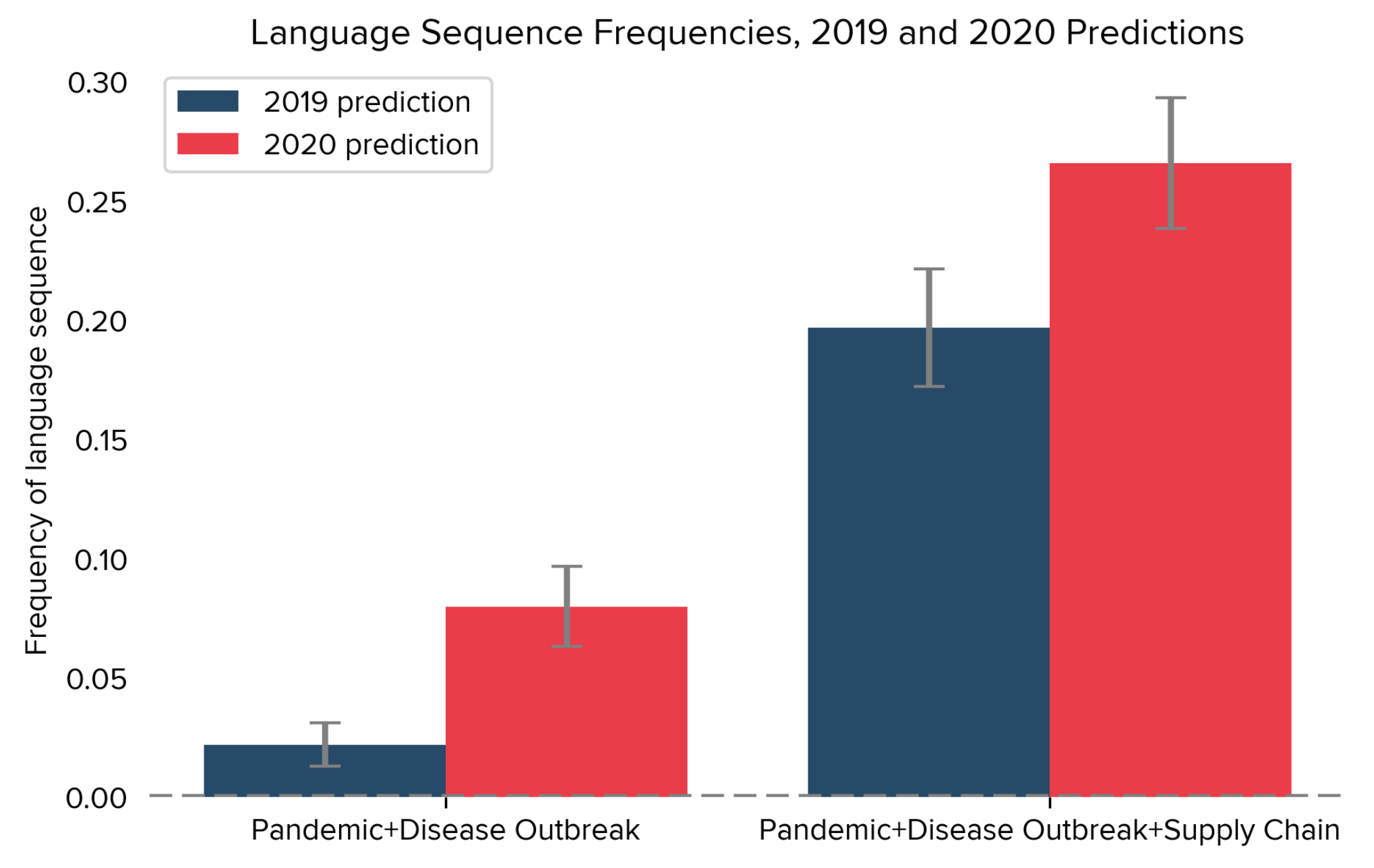
How Do Investors Value ESG? [Preprint]
with Malcolm Baker and Mark Egan
Presented at NBER Corporate Finance Meeting (2023)
Abstract
Environmental, social, and governance (ESG) objectives have risen to near the top of the agenda for investment management firms, corporate executives, and boards, driven in large part by their perceptions of shareholder interest. We quantify the value that shareholders place on ESG using a revealed preference approach, where shareholders pay higher fees for ESG-oriented index funds in exchange for their financial and non-financial benefits. We find that investors are willing, on average, to pay 20 basis points more per annum for an investment in a fund with an ESG mandate as compared to an otherwise identical mutual fund without an ESG mandate, suggesting that investors as a group expect commensurately higher pre-fee, gross returns, either financial or non-financial, from an ESG mandate. Our point estimate rises from 9 basis points in 2019, the first year in our sample, to as much as 28 basis points in 2022. When we consider that the holdings of ESG and non-ESG index funds overlap, when we measure the ESG ratings of these holdings, when we consider funds’ grades on environmental and social issues, and when we focus on 401(k) participants who report being concerned about climate change or who work in industries with lower levels of emissions, we find that the implicit value that investors place on ESG stocks is higher still. We offer tentative conclusions on how value is split among investors, intermediary profits, and firm costs of capital.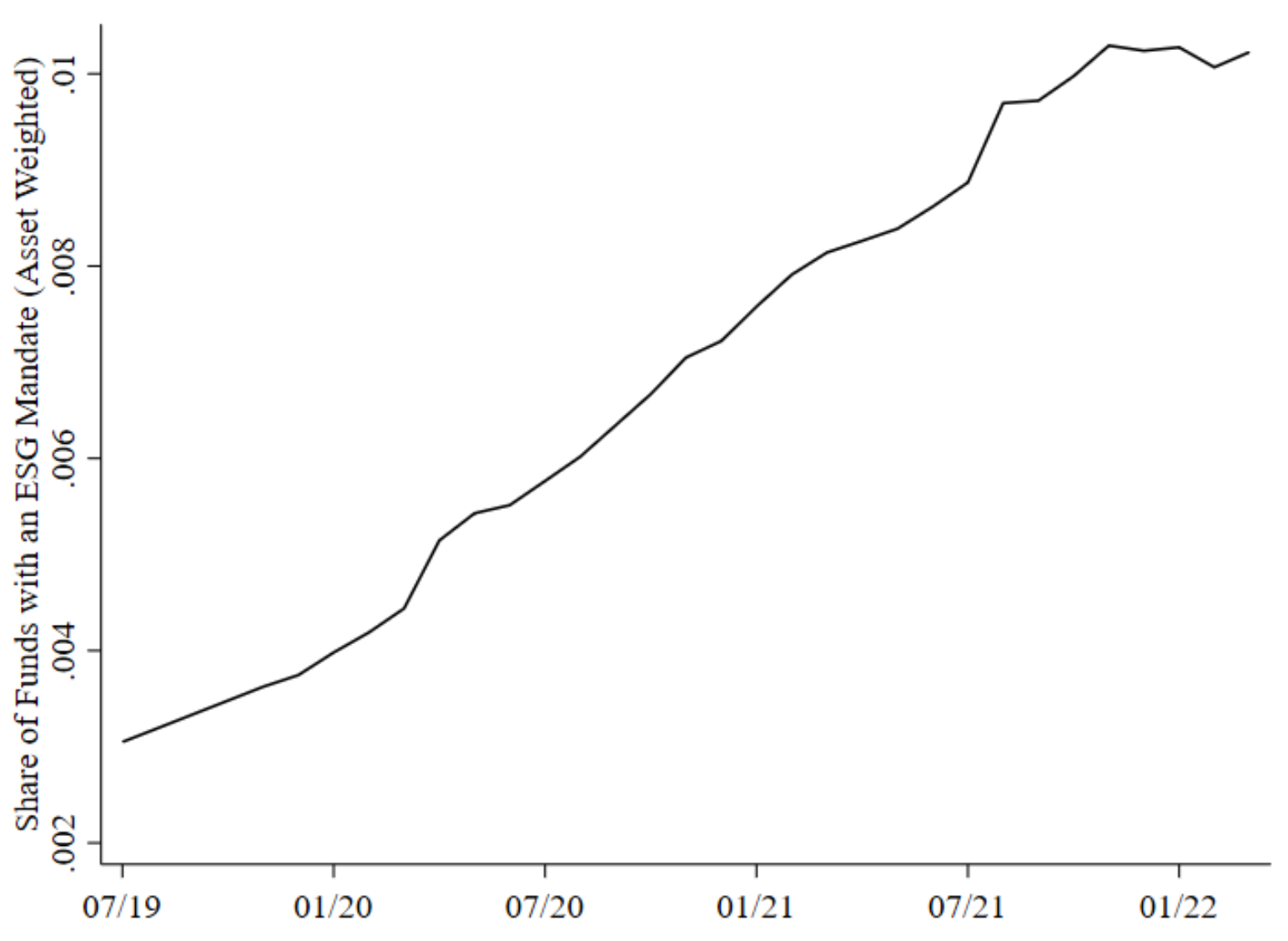
In Progress
Partisanship and Economic Beliefs
with Johnny Tang
Presented at Allied Social Science Associations, Annual Meeting (2022)
An Economic Approach to Machine Learning in Health Policy
with N. Meltem Daysal, Sendhil Mullainathan, Ziad Obermeyer, and Mircea Trandafir
Presented at National Bureau of Economic Research, Conference on Machine Learning in Healthcare (2021)
Published
The Harvard USPTO Patent Dataset [PDF]
with Mirac Suzgun, Luke Melas-Kyriazi, Scott Duke Kominers and Stuart M. Shieber
Published in Neural Information Processing Systems, Datasets and Benchmarks (2023)
Abstract
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Although the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, ML offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike previously proposed patent datasets in NLP, HUPD contains the inventor-submitted versions of patent applications—not the final versions of granted patents—thereby allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured metadata alongside the text of patent filings: By providing each application’s metadata along with all of its text fields, the dataset enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on the types of research HUPD makes possible, we introduce a new task to the NLP community—namely, binary classification of patent decisions. We additionally show the structured metadata provided in the dataset enables us to conduct explicit studies of concept shifts for this task. Finally, we demonstrate how our dataset can be used for three additional tasks: multi-class classification of patent subject areas, language modeling, and summarization. Overall, HUPD is one of the largest multi-purpose NLP datasets containing domain-specific textual data, along with well-structured bibliographic metadata, and aims to advance research extending language and classification models to diverse and dynamic real-world data distributions.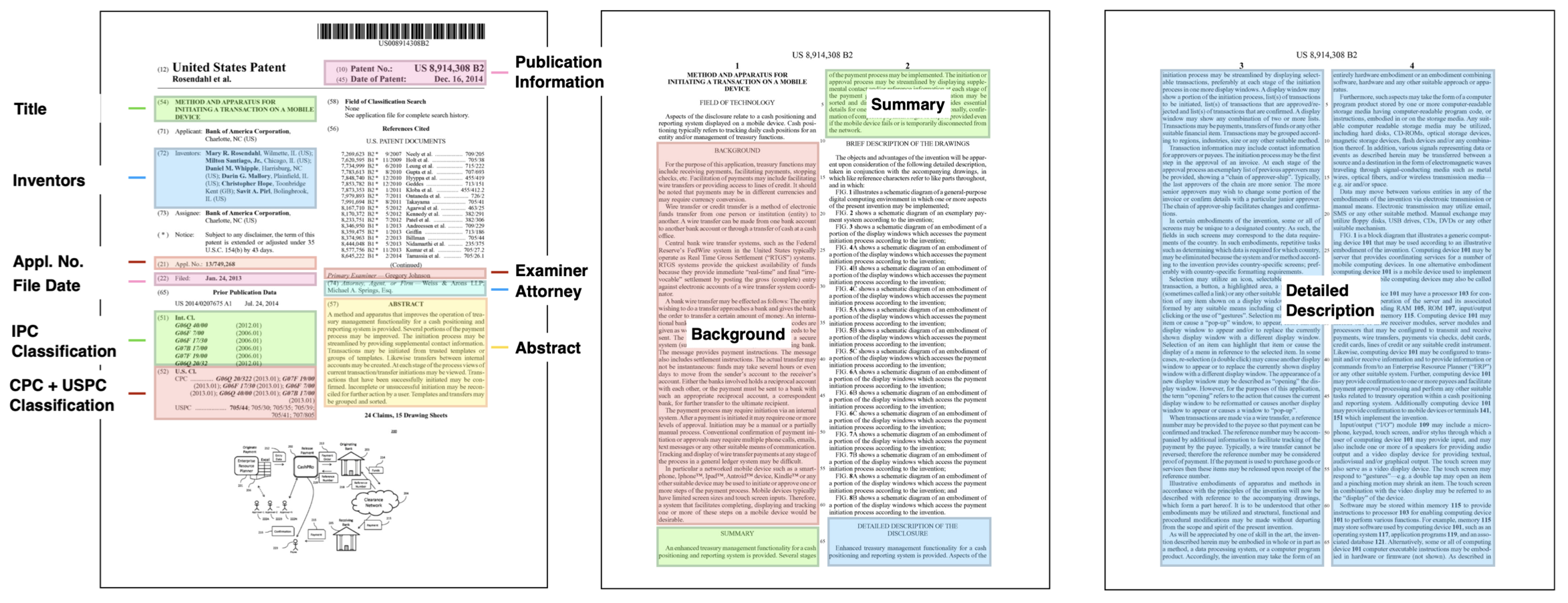
A Semantic Approach to Financial Fundamentals [PDF]
with Jiafeng Chen
Presented at FinNLP, Workshop on Financial Technology and Natural Language Processing (2020)
Abstract
The structure and evolution of firms’ operations are essential components of modern financial analyses. Traditional text-based approaches have often used standard statistical learning methods to analyze news and other text relating to firm characteristics, which may shroud key semantic information about firm activity. In this paper, we present the Semantically-Informed Financial Index, an approach to modeling firm characteristics and dynamics using embeddings from transformer models. As opposed to previous work that uses similar techniques on news sentiment, our methods directly study the business operations that firms report in filings, which are legally required to be accurate. We develop text-based firm classifications that are more informative about fundamentals per level of granularity than established metrics, and use them to study the interactions between firms and industries. We also characterize a basic model of business operation evolution. Our work aims to contribute to the broader study of how text can provide insight into economic behavior.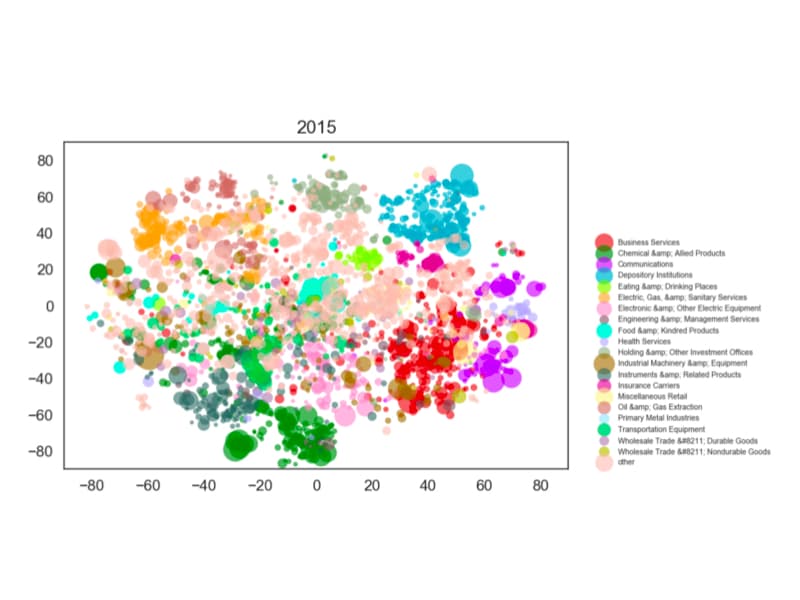
Constitutional Dimensions of Predictive Algorithms in Criminal Justice [PDF]
with Michael Brenner, Jeannie Suk Gersen, Michael Haley, Matthew Lin, Amil Merchant, Richard Jagdishwar Millett, and Drew Wegner
Published in Harvard Civil Rights-Civil Liberties Law Review (2020)
Abstract
This Article analyzes constitutional issues presented by the use of proprietary risk assessment technology and how courts can best address them. Focusing on due process and equal protection, this Article explores potential avenues for constitutional challenges to risk assessment technology at federal and state levels, and outlines how these instruments might be retooled to increase accuracy and accountability while satisfying constitutional standards.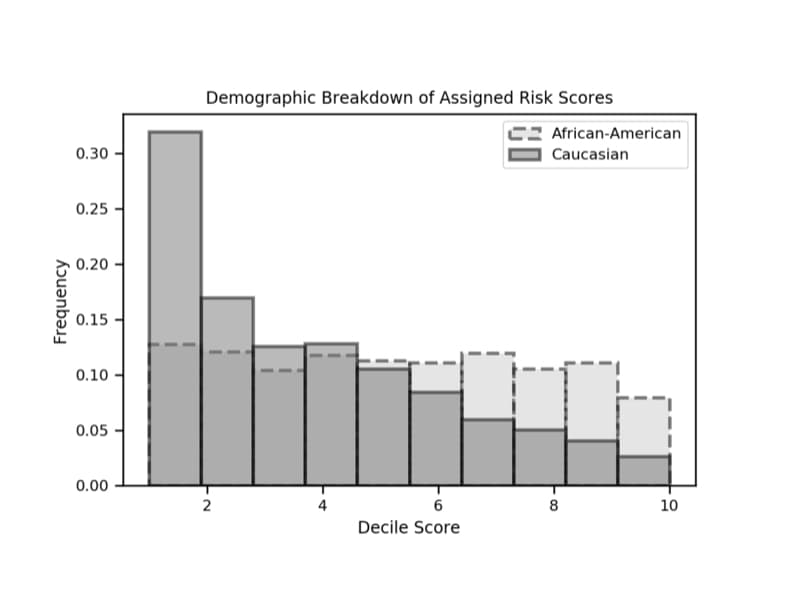
Robust Classification of Financial Risk [PDF]
with Kojin Oshiba, Daniel Giebisch and Yaron Singer
Presented at Neural Information Processing Systems, AI in Financial Services Workshop (2018)
Abstract
Algorithms are increasingly common components of high-impact decision-making, and a growing body of literature on adversarial examples in laboratory settings indicates that standard machine learning models are not robust. This suggests that real-world systems are also susceptible to manipulation or misclassification, which especially poses a challenge to machine learning models used in financial services. We use the loan grade classification problem to explore how machine learning models are sensitive to small changes in user-reported data, using adversarial attacks documented in the literature and an original, domain-specific attack. Our work shows that a robust optimization algorithm can build models for financial services that are resistant to misclassification on perturbations. To the best of our knowledge, this is the first study of adversarial attacks and defenses for deep learning in financial services.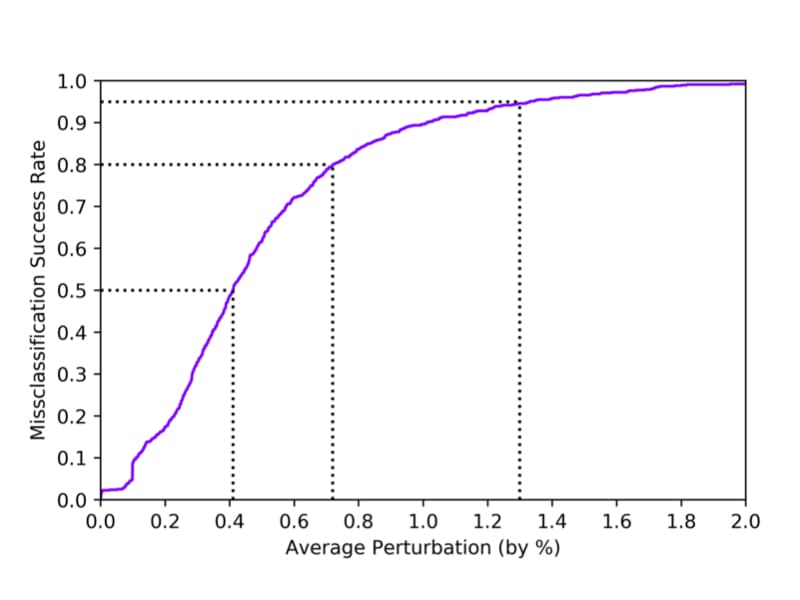
Non-Refereed
StoriesLM: A Family of Language Models With Sequentially-Expanding Pretraining Windows [Link]
Abstract
StoriesLM is a family of language models with sequentially-expanding pretraining windows. The pretraining data for the model family comes from the American Stories dataset—a collection of language from historical American news articles. The first language model in the StoriesLM family is pretrained on language data from 1900. Each subsequent language model further trains the previous year’s model checkpoint using data from the following year, up until 1963. The model family is available on the Hugging Face Hub.
Machine Learning for Health 2020: Advancing Healthcare for All [PDF]
with Subhrajit Roy, Emily Alsentzer, Matthew B. A. McDermott, Fabian Falck, Ioana Bica, Griffin Adams, Stephen Pfohl, Brett Beaulieu-Jones, Tristan Naumann, and Stephanie L. Hyland
Published in Proceedings of Machine Learning Research, Vol. 136 (2020)
Teaching
Algorithms and Behavioral Science [14.163]
Teaching Assistant, Spring 2024
Political Economics [Econ 1425]
Teaching Fellow, Spring 2023 & Spring 2022
Certificate of Distinction in Teaching
Artificial Intelligence Meets Human Intelligence [Wintersession Course]
Course Head, Winter 2022