I am an Assistant Professor of Finance and Applied AI at the University of Chicago Booth School of Business. I am supported by the Biehler Junior Faculty Fellowship and the Fama-Miller Center.
I received my Ph.D. in Economics, S.M. in Applied Mathematics, and A.B. in Computer Science, summa cum laude, from Harvard.
Research
Working Papers
-
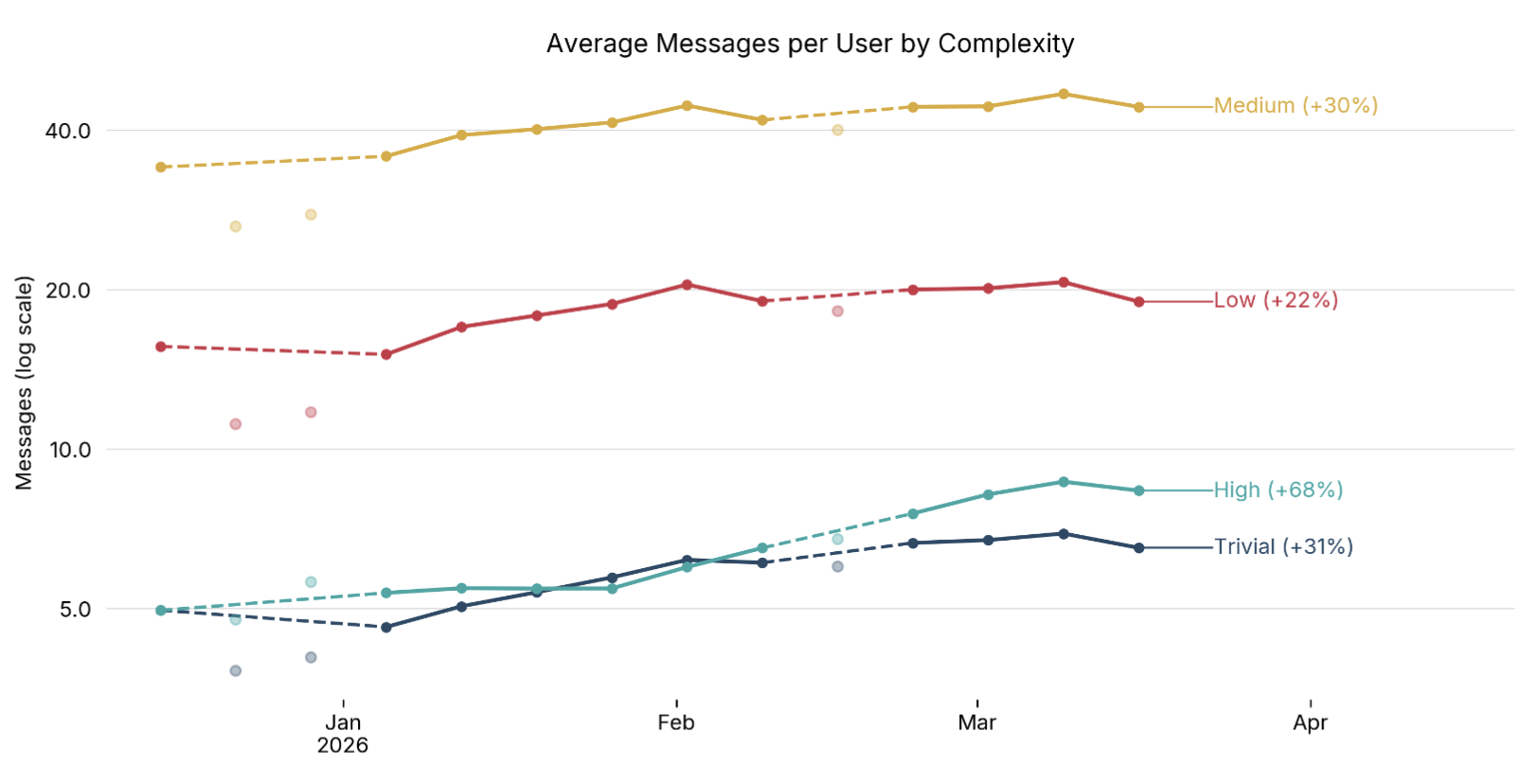
Returns to Intelligence
Presentations: AI and Economics Summer Conference
Abstract
When AI improves, how does usage respond? We document a Jevons-like effect in AI demand: Improved capabilities increase usage, and shift AI use toward more complex tasks. We study firms that use the coding platform Cursor. After improvements in model capabilities in late 2025, workers sent 44% more agent messages per week on the platform. The initial increase was larger for lower-complexity messages, though usage shifted over time to higher-complexity messages. The increase was stronger in smaller, private, and newer firms, as well as in tasks with more cross-system dependencies like architecture and deployment work. The evidence is consistent with higher latent AI demand from firms that are organized more flexibly and can scale production more effectively. We discuss implications for investment by model providers, and consider how future usage growth relates to both competition between firms and downstream demand.
-
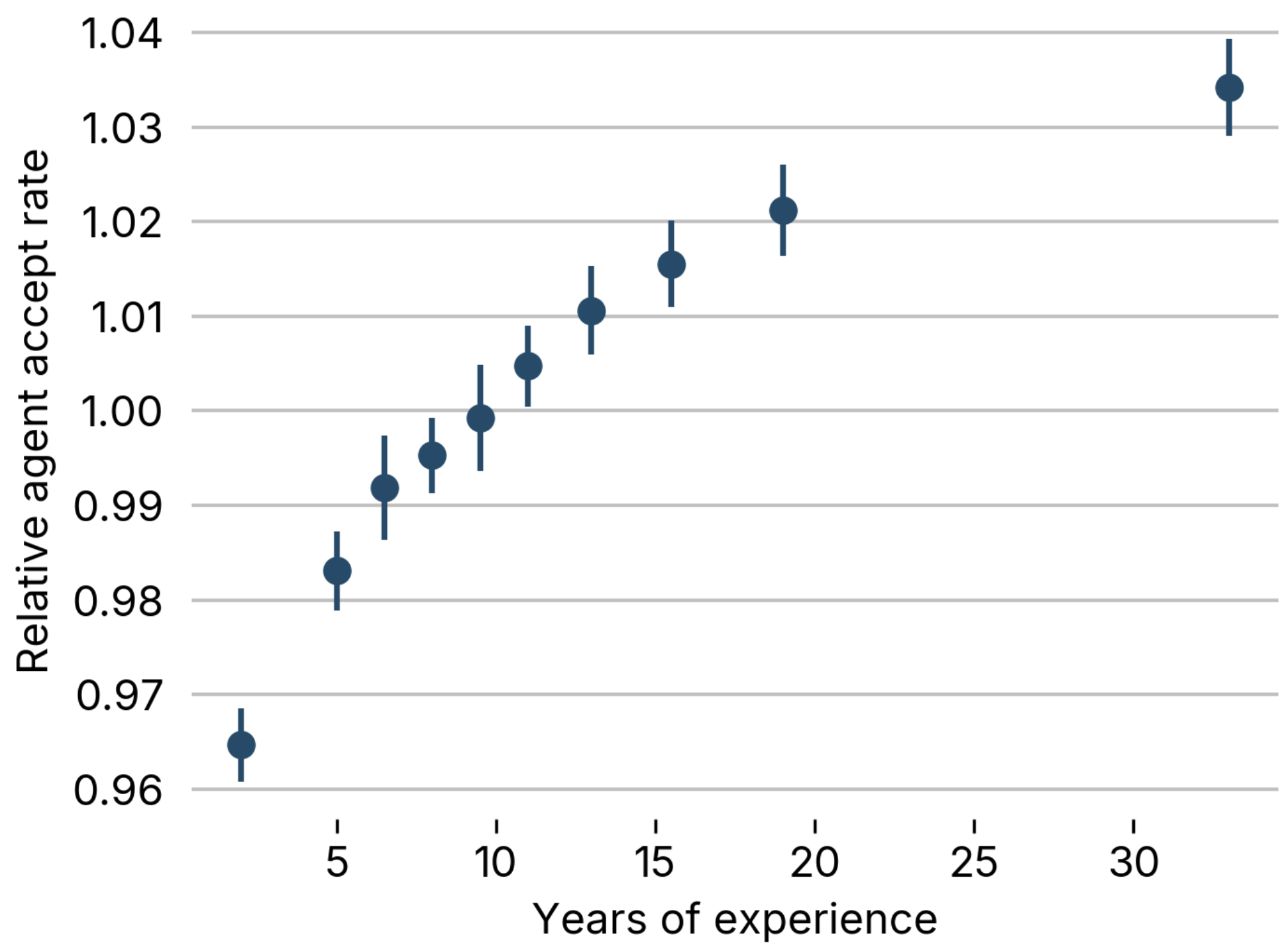
AI Agents and Higher-Order Work
Presentations: NBER Labor Studies Meeting, NBER Productivity, Innovation, and Entrepreneurship Meeting
Abstract
How do AI agents influence knowledge work? This paper finds that agents shift worker effort from implementation to supervision, which especially benefits verifiable work and expert workers. I analyze data from the coding platform Cursor to study agents in software production. First, I find that workers have become less likely to produce output manually after AI agents were introduced, and are more likely to delegate work to agents. Second, workers use agents for abstract, higher-order tasks like delegation, context gathering, and planning. Third, agents are used more frequently in settings with easier-to-verify work outputs. Fourth, experienced workers appear more skilled at delegating work to agents—they ask fewer questions, seek more alignment through planning, and accept agent outputs at higher rates. Fifth, using variation from the platform's feature release timeline, I find that agents increase software output, especially for firms with more verifiable work and more experienced workers. The complementarity between AI agents and expertise contrasts with evidence on non-agentic AI tools, which workers are more likely to use for support than for delegation. Taken together, the results suggest that the returns to expertise may rise as knowledge work becomes more abstract.
-
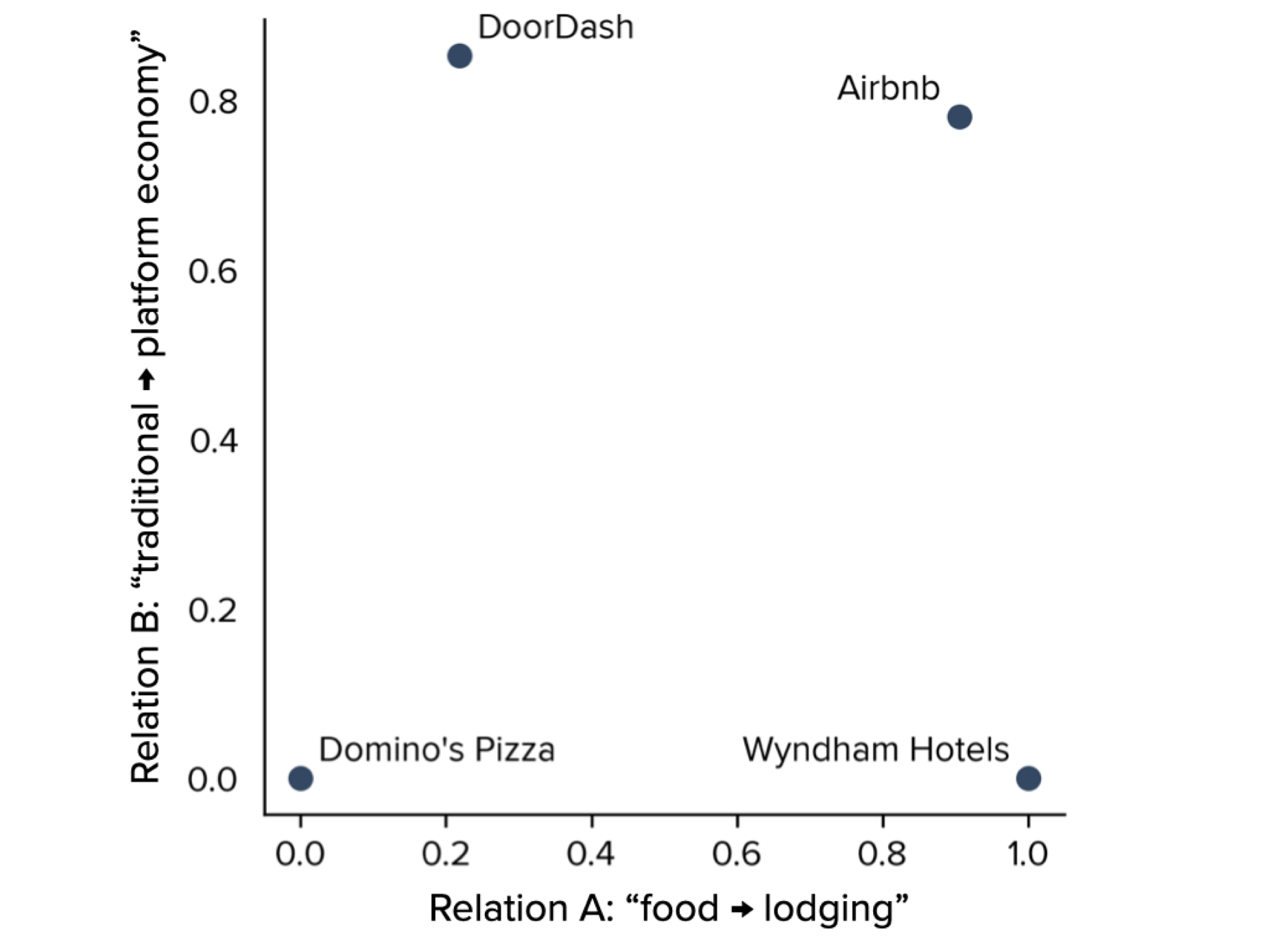
Economic Representations
Presentations: Machine Learning in Economics Summer Conference, NBER Asset Pricing Meeting, Econometric Society World Congress
Abstract
Valuations depend on how people categorize, perceive, or otherwise represent economic objects. This paper develops a measure of how the market represents firms, and uses this measure to study stock valuations. I train an algorithm to structure language from financial news into embeddings—vectors that quantify the economic features and themes in each firm’s news coverage. I show that a firm’s vector representation is informative of how the market perceives its business model. Representations explain cross-sectional variation in stock valuations, cash flow forecasts, and return correlations. Changes in representation help to explain changes in stock prices. Some changes in representations and prices are forecastable, and indicate that some of the explained variation in stock valuations stems from misperception. I find that misperception and misvaluation can intensify when a firm’s news coverage includes attention-drawing features—like “internet” in the late 1990s or “AI” in the early 2020s.
-
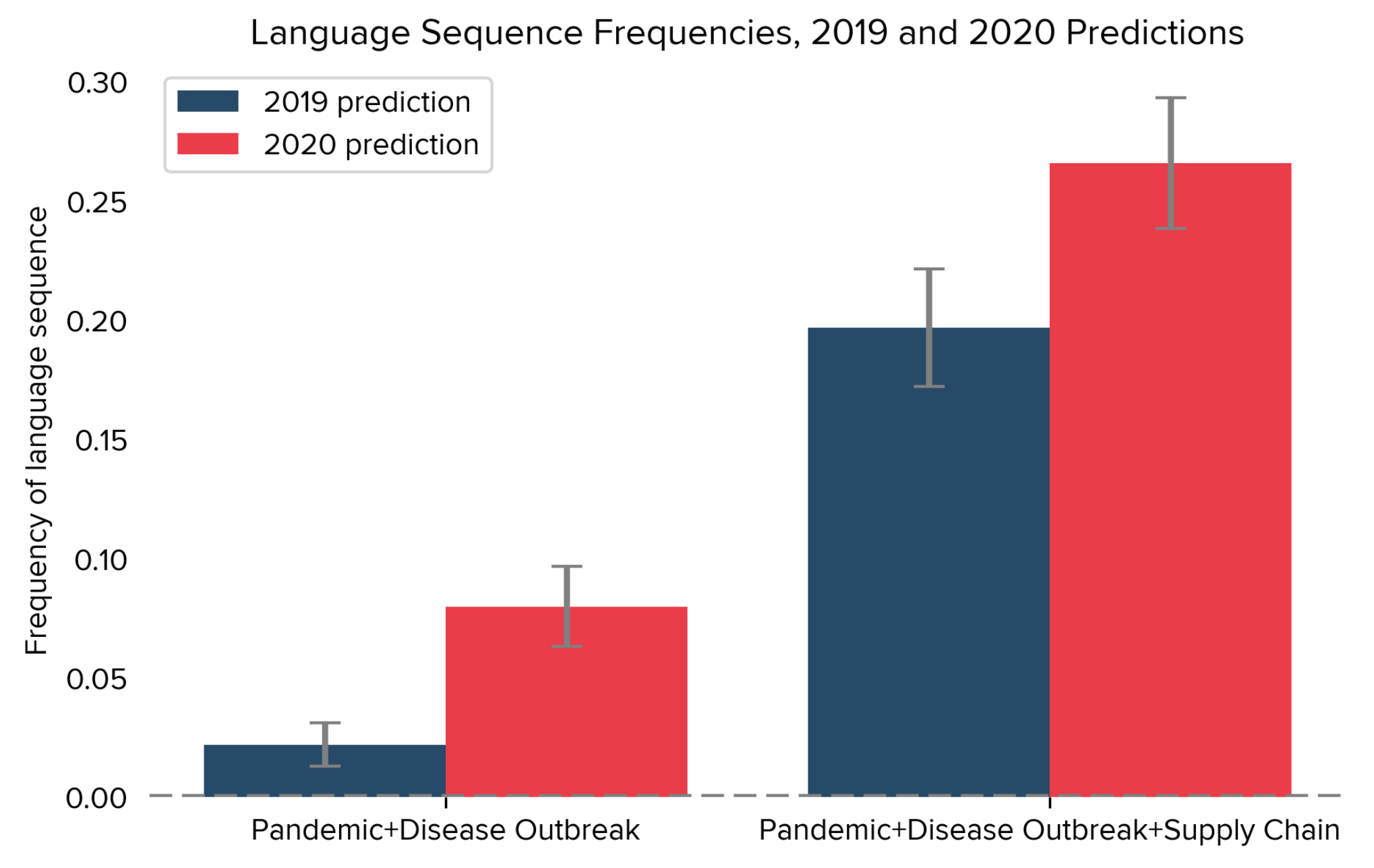
Lookahead Bias in Pretrained Language Models
Presentations: NBER Big Data Meeting, ICML Workshop on Data in Generative Models
Abstract
Empirical analysis that uses outputs from pretrained language models can be subject to a form of temporal lookahead bias. This bias arises when a language model’s pretraining data contains information about the future, which then leaks into analysis that should only use information from the past. In this paper we develop direct tests for lookahead bias, based on the assumption that some events are unpredictable given a prespecified information set. Using these tests, we find evidence of lookahead bias in two applications of language models to social science: Predicting risk factors from corporate earnings calls and predicting election winners from candidate biographies. We additionally discuss the limitations of prompting-based approaches to counteract this bias. The issues we raise can be addressed by using models whose pretraining data is free of survivorship bias and contains only language produced prior to the analysis period of interest.
-
An Economic Approach to Machine Learning in Health Policy
Presentations: NBER Conference on Machine Learning in Healthcare, Responsible ML in Healthcare Workshop
Abstract
We consider the health effects of “precision” screening policies for cancer guided by algorithms. We show that machine learning models that predict breast cancer from health claims data outperform models based on just age and established risk factors. We estimate that screening women with high predicted risk of invasive tumors would reduce the long-run incidence of later-stage tumors by 40%. Screening high-risk women would also lead to half the rate of cancer overdiagnosis that screening low-risk women would. We show that these results depend crucially on the machine learning model’s prediction target. A model trained to predict positive mammography results leads to policies with weaker health effects and higher rates of overdiagnosis than a model trained to predict invasive tumors.
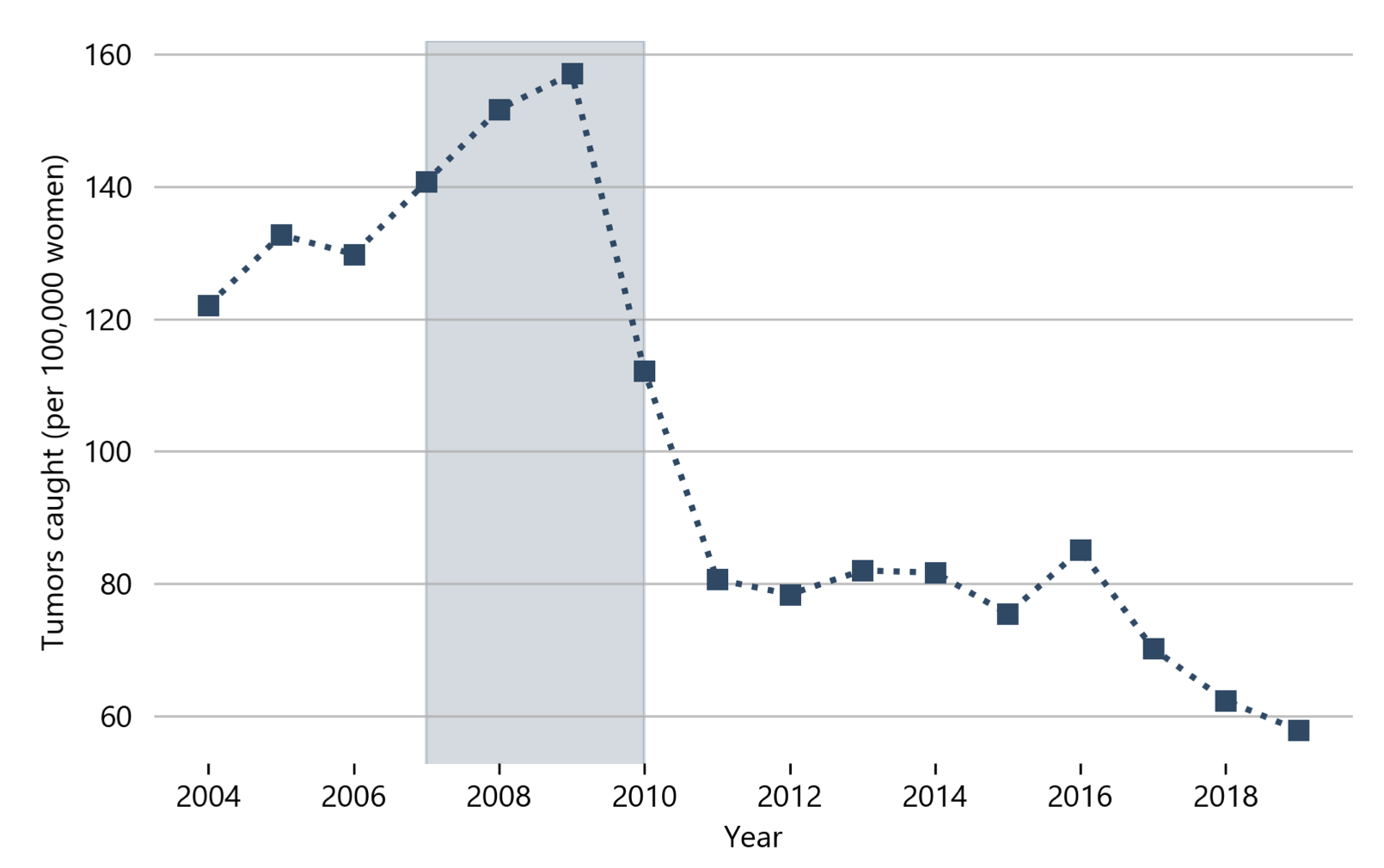
-
Demand for ESG
Presentations: NBER Corporate Finance Meeting
Abstract
We quantify the value investors place on environmental, social, and governance (ESG) objectives over time and space using a revealed preference approach. Our approach measures investors' willingness to pay for ESG-oriented index funds in exchange for their financial and non-financial benefits. We find that the premium that investors assign to index funds with an ESG mandate rose from 3 basis points in 2019 to a peak of 17 basis points in 2020, before turning negative in 2022 and falling to negative 33 basis points in 2023. The boom and bust in willingness to pay is more pronounced among institutional investors (versus retail investors) and equity investors (versus fixed income investors). In contrast to US investors, European investors' willingness to pay for ESG started at a higher level in 2019 and remains strongly positive in 2023. Although differences in fund holdings explain some of the demand for ESG-oriented funds, much of it is driven by the ESG label itself, which may leave investors susceptible to greenwashing. When we apply our framework to the cross-section of 401(k) participant portfolios, we find that investors in climate-conscious areas and low-emission industries exhibit higher demand for ESG. We offer tentative conclusions on how value is split among investors, intermediary profits, and firm costs of capital.
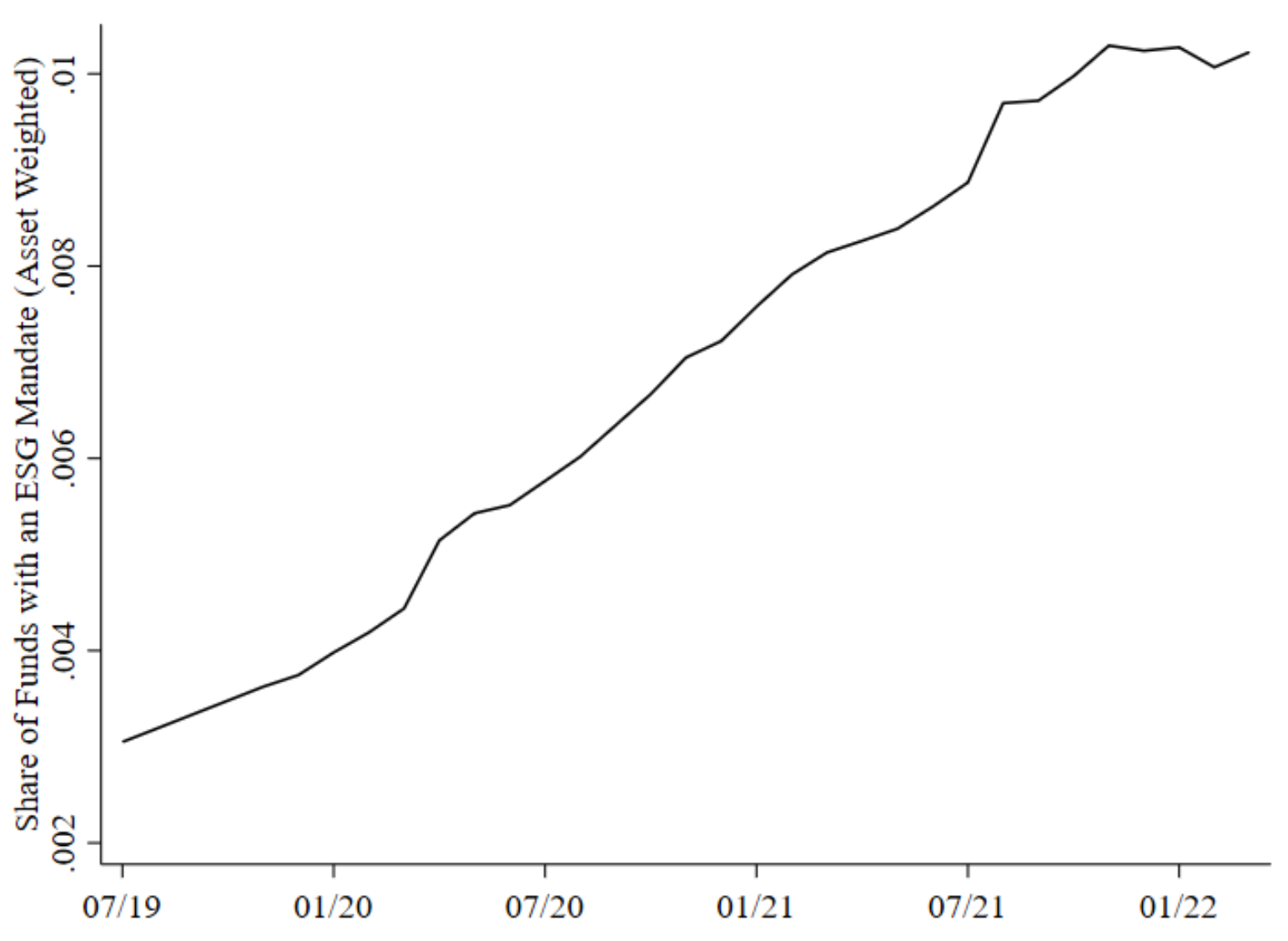
-
StoriesLM: A Family of Language Models With Time-Indexed Training Data
Abstract
Empirical research that uses off-the-shelf language models faces credibility and replicability issues. First, standard LLM training procedures can introduce lookahead bias. Many language models are trained on contemporary datasets, which can lead information from the future to leak into analysis that should only use information from the past. Second, many LLM providers regularly update their models. After these updates, researchers may be unable to replicate previous model outputs. To avoid these issues, researchers can use language models with time-indexed pretraining data, or "time subscripts." StoriesLM is a family of language models with sequential, time-indexed pretraining data. The model is trained on the American Stories dataset (Dell et al., 2024)—a collection of language from historical American news articles. The first language model in the StoriesLM family is trained on language data from 1900. Each subsequent language model further trains on the previous year’s model checkpoint, using data from the following year. Because each model has a time subscript, analysis that considers events from after the training period avoids lookahead bias from pretraining. In addition, because each model's weights are fixed, this model family can be applied to produce replicable results.
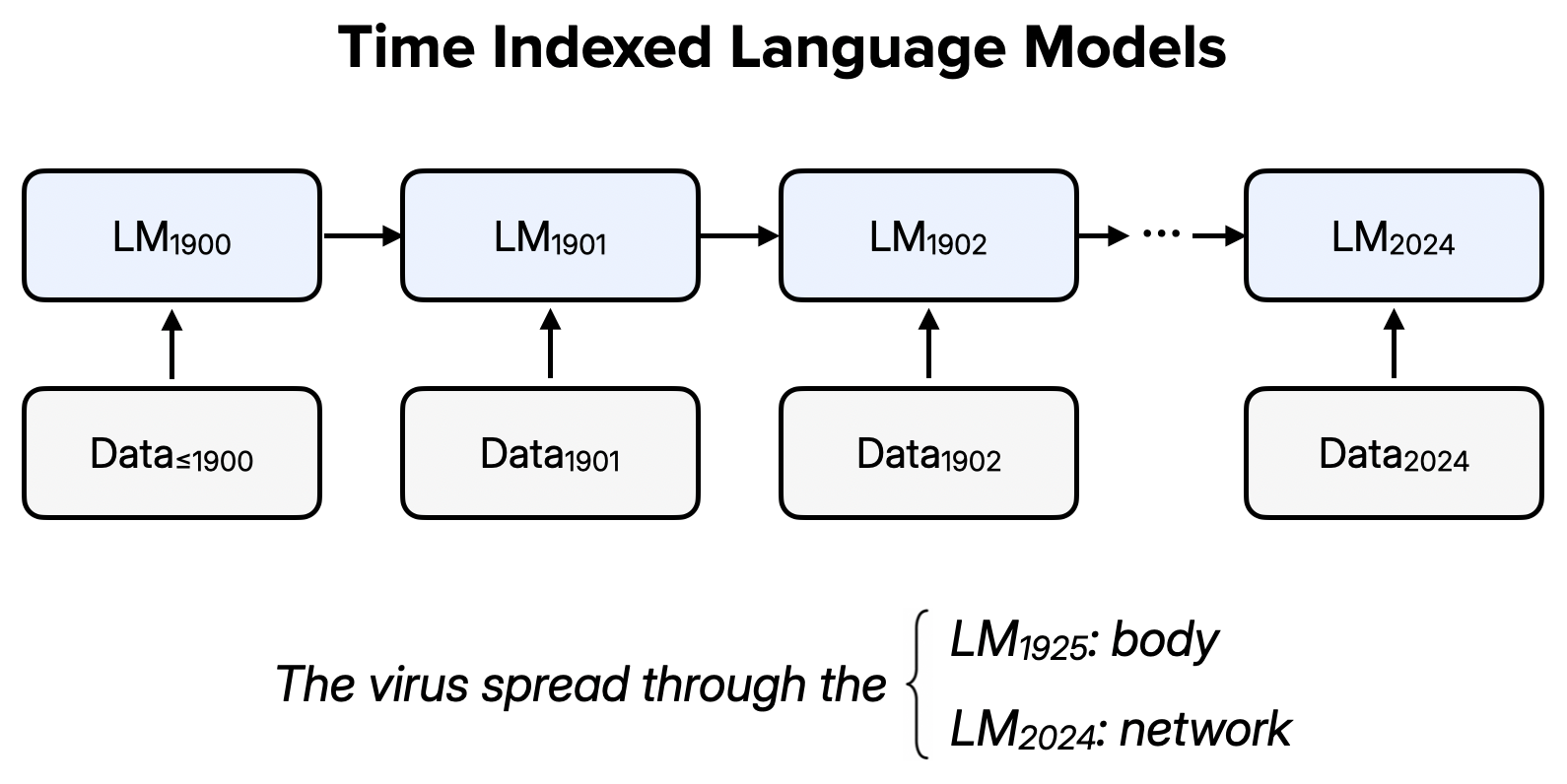







In Preparation
-
Partisanship and Macroeconomic Beliefs
Presentations: Winter Meeting of the Econometric Society
Abstract
We introduce new measures of economic partisanship based on language similarity to Republican- and Democrat-aligned economic reporting on cable news programs. We apply our methods to corporate executives’ earnings calls speeches to measure economic partisanship for executives across more than 5,000 US firms. We find partisan differences in corporate executives’ language that are not explained by variation across industries, locations, and firm characteristics. More partisan executives display higher economic sentiment after their party wins the presidency, which declines as the presidential term progresses. Partisan executives also pay more attention to politically-favorable macroeconomic topics. These differences in language predict differences in decision-making: After the 2016 election, firms with executives who used more Republican-aligned economic language invested more and issued more optimistic earnings guidance, but did not earn higher revenues.
Published
-
The Harvard USPTO Patent Dataset
Published in Neural Information Processing Systems, Datasets and Benchmarks (Spotlight, 2023)
Abstract
Innovation is a major driver of economic and social development, and information about many kinds of innovation is embedded in semi-structured data from patents and patent applications. Although the impact and novelty of innovations expressed in patent data are difficult to measure through traditional means, ML offers a promising set of techniques for evaluating novelty, summarizing contributions, and embedding semantics. In this paper, we introduce the Harvard USPTO Patent Dataset (HUPD), a large-scale, well-structured, and multi-purpose corpus of English-language patent applications filed to the United States Patent and Trademark Office (USPTO) between 2004 and 2018. With more than 4.5 million patent documents, HUPD is two to three times larger than comparable corpora. Unlike previously proposed patent datasets in NLP, HUPD contains the inventor-submitted versions of patent applications—not the final versions of granted patents—thereby allowing us to study patentability at the time of filing using NLP methods for the first time. It is also novel in its inclusion of rich structured metadata alongside the text of patent filings: By providing each application’s metadata along with all of its text fields, the dataset enables researchers to perform new sets of NLP tasks that leverage variation in structured covariates. As a case study on the types of research HUPD makes possible, we introduce a new task to the NLP community—namely, binary classification of patent decisions. We additionally show the structured metadata provided in the dataset enables us to conduct explicit studies of concept shifts for this task. Finally, we demonstrate how our dataset can be used for three additional tasks: multi-class classification of patent subject areas, language modeling, and summarization. Overall, HUPD is one of the largest multi-purpose NLP datasets containing domain-specific textual data, along with well-structured bibliographic metadata, and aims to advance research extending language and classification models to diverse and dynamic real-world data distributions.
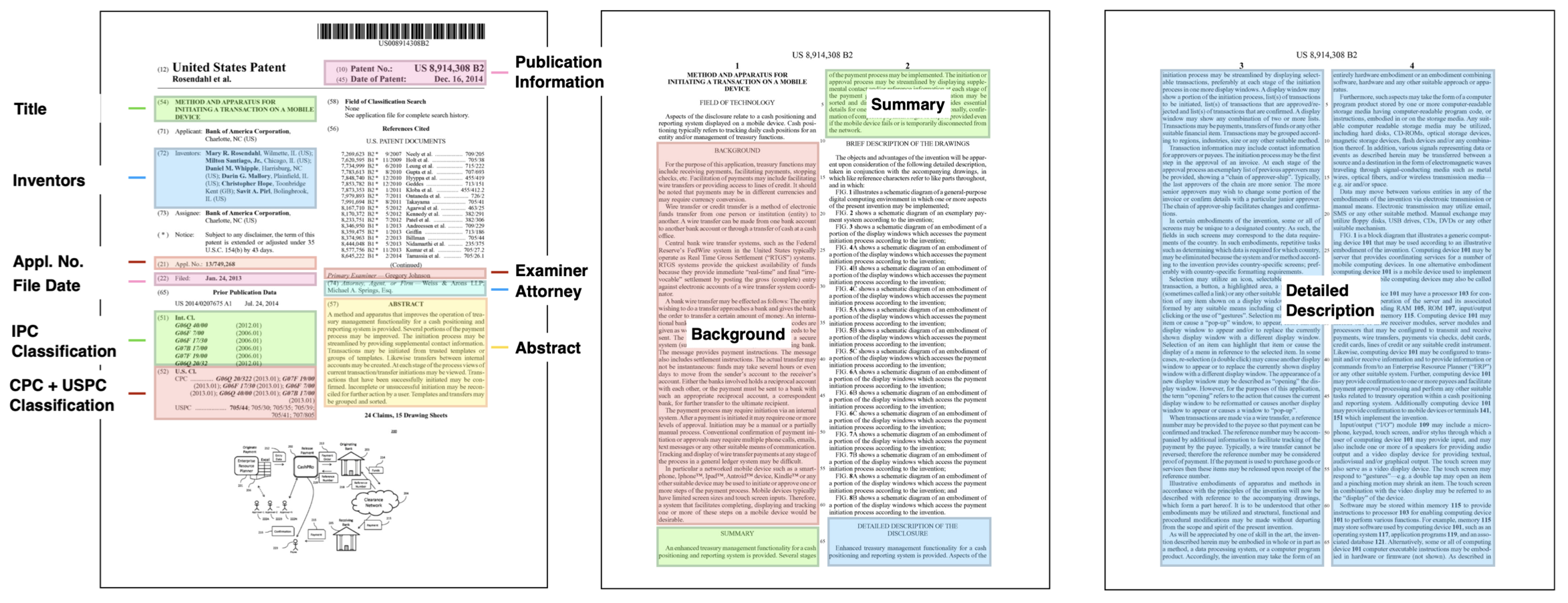
-
A Semantic Approach to Financial Fundamentals
Presented at FinNLP, Workshop on Financial Technology and Natural Language Processing (2020)
Abstract
The structure and evolution of firms’ operations are essential components of modern financial analyses. Traditional text-based approaches have often used standard statistical learning methods to analyze news and other text relating to firm characteristics, which may shroud key semantic information about firm activity. In this paper, we present the Semantically-Informed Financial Index, an approach to modeling firm characteristics and dynamics using embeddings from transformer models. As opposed to previous work that uses similar techniques on news sentiment, our methods directly study the business operations that firms report in filings, which are legally required to be accurate. We develop text-based firm classifications that are more informative about fundamentals per level of granularity than established metrics, and use them to study the interactions between firms and industries. We also characterize a basic model of business operation evolution. Our work aims to contribute to the broader study of how text can provide insight into economic behavior.
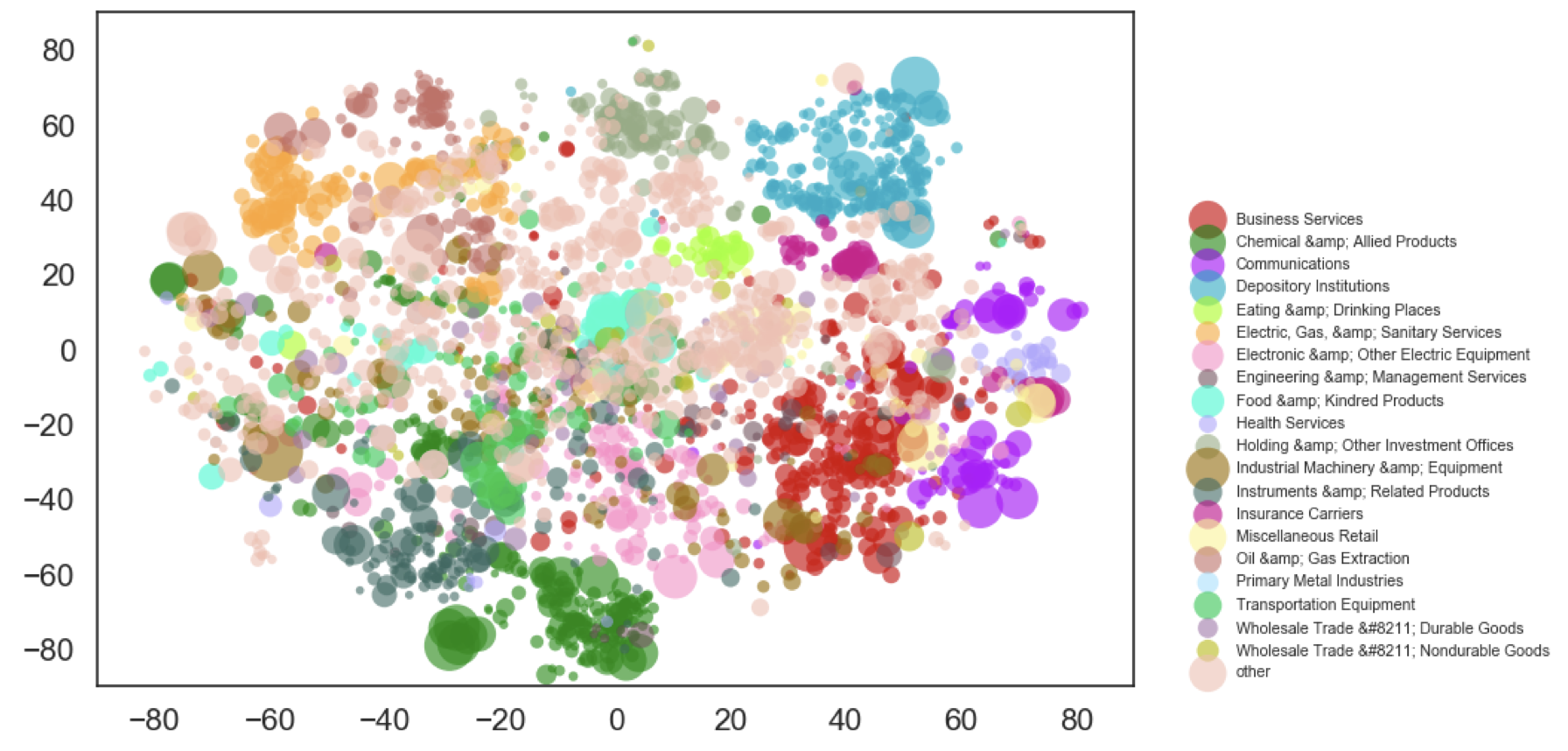
-
Constitutional Dimensions of Predictive Algorithms in Criminal Justice
Published in Harvard Civil Rights-Civil Liberties Law Review (2020)
Abstract
This Article analyzes constitutional issues presented by the use of proprietary risk assessment technology and how courts can best address them. Focusing on due process and equal protection, this Article explores potential avenues for constitutional challenges to risk assessment technology at federal and state levels, and outlines how these instruments might be retooled to increase accuracy and accountability while satisfying constitutional standards.
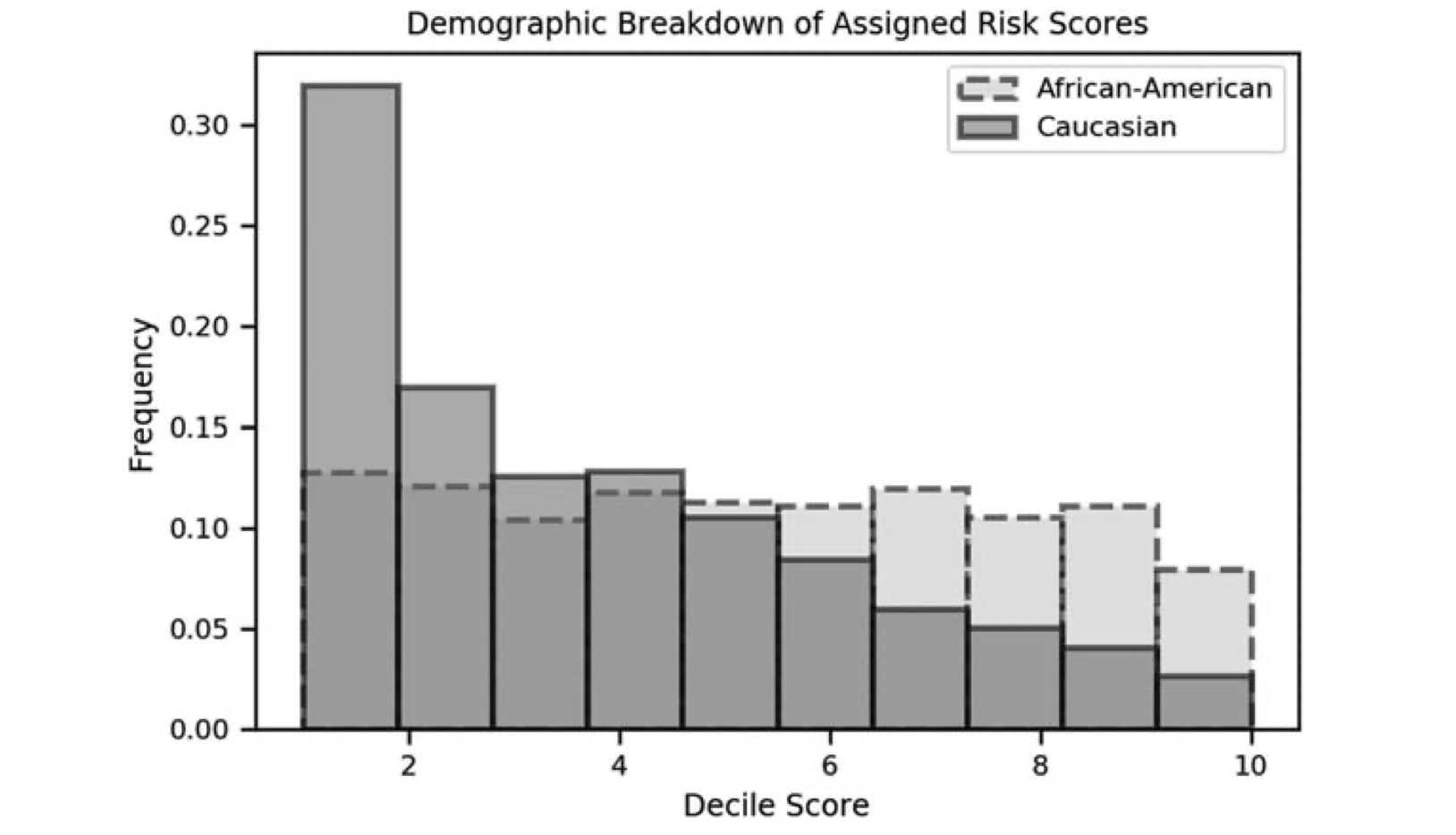
-
Robust Classification of Financial Risk
Presented at Neural Information Processing Systems, AI in Financial Services Workshop (2018)
Abstract
Algorithms are increasingly common components of high-impact decision-making, and a growing body of literature on adversarial examples in laboratory settings indicates that standard machine learning models are not robust. This suggests that real-world systems are also susceptible to manipulation or misclassification, which especially poses a challenge to machine learning models used in financial services. We use the loan grade classification problem to explore how machine learning models are sensitive to small changes in user-reported data, using adversarial attacks documented in the literature and an original, domain-specific attack. Our work shows that a robust optimization algorithm can build models for financial services that are resistant to misclassification on perturbations. To the best of our knowledge, this is the first study of adversarial attacks and defenses for deep learning in financial services.
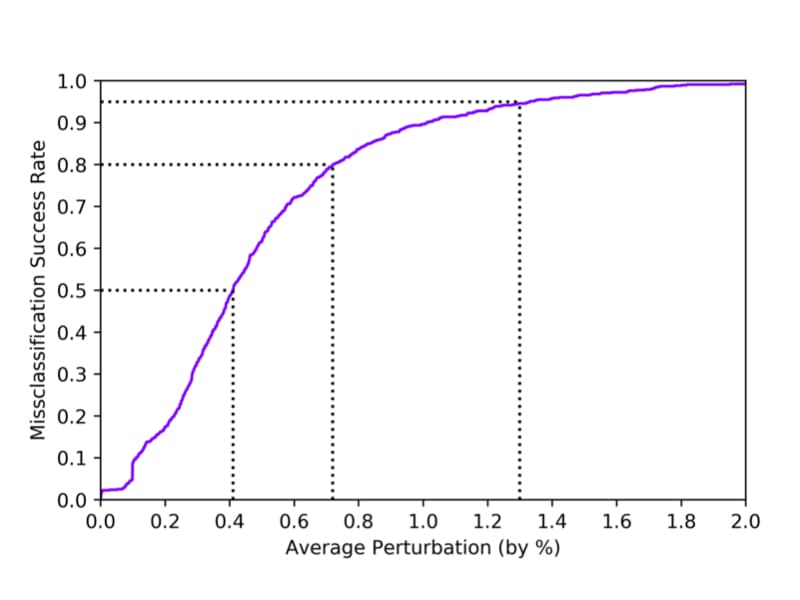




Non-Refereed
-
Machine Learning for Health 2020: Advancing Healthcare for All
Published in Proceedings of Machine Learning Research, Vol. 136 (2020)

Teaching
- Algorithms and Behavioral Science [MIT 14.163] — Teaching Assistant, Spring 2024
- Political Economics [Harvard Econ 1425] — Teaching Assistant, Spring 2023 & Spring 2022 — Certificate of Distinction in Teaching
- Artificial Intelligence Meets Human Intelligence [Harvard Wintersession Course] — Course Head, Winter 2022
- Artificial Intelligence [Harvard CS 182] — Teaching Assistant, Fall 2017