Writing
-
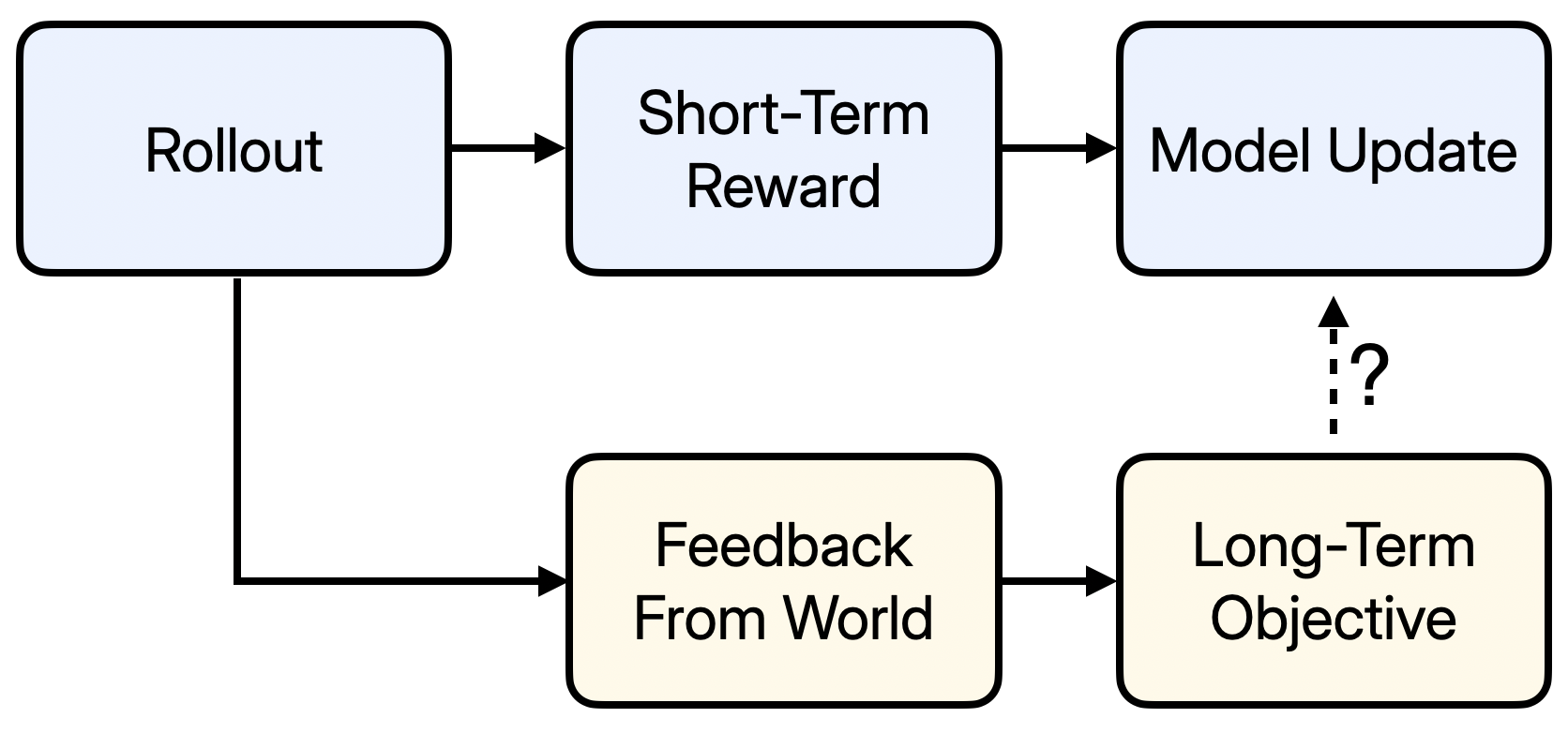
The Reward Horizon Problem
Models are trained on short-horizon rewards, but used for longer-horizon economic objectives.
-
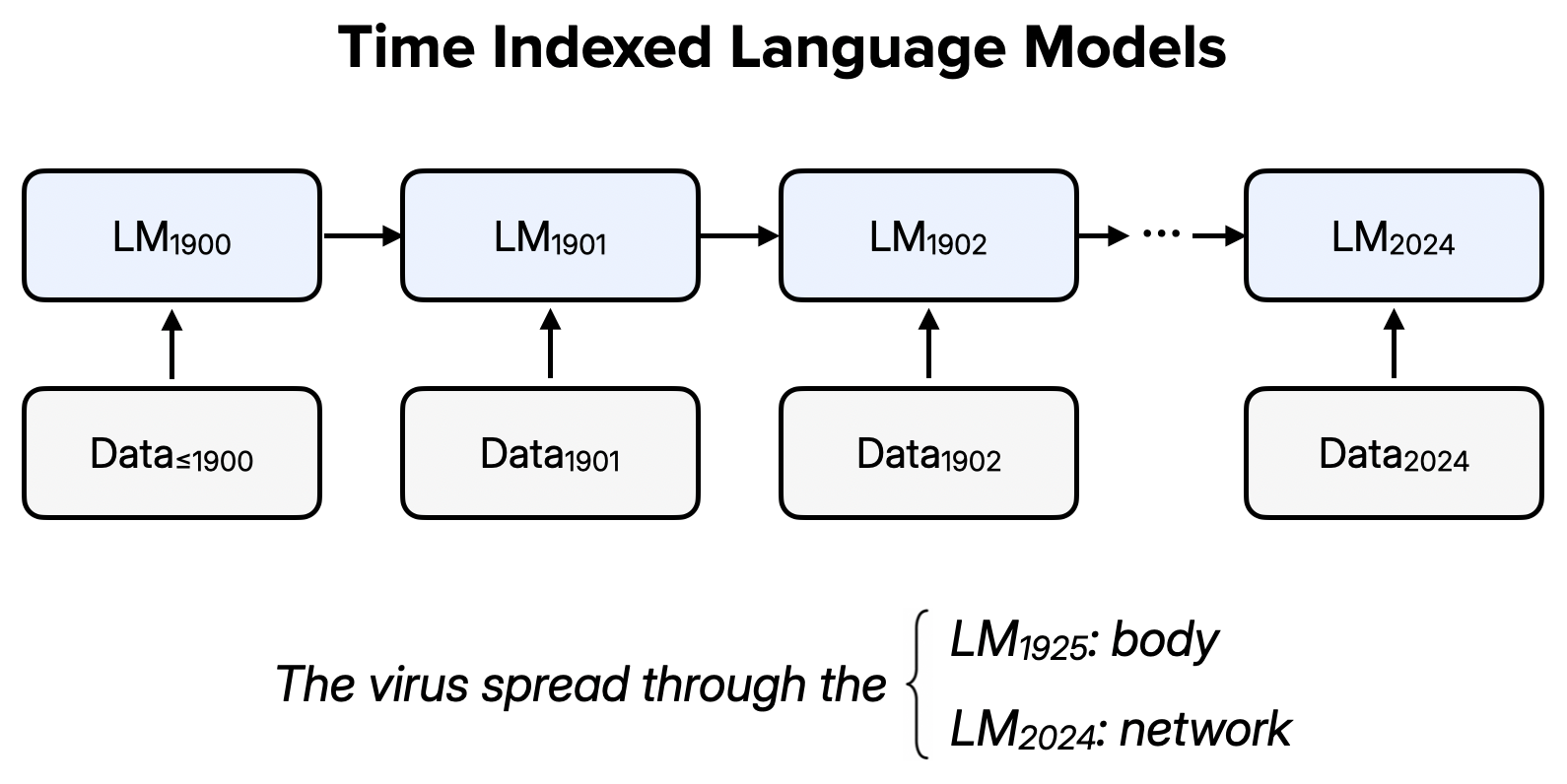
StoriesLM-v2: A Family of Language Models With Time-Indexed Training Data
StoriesLM-v2 is a family of 125 encoder-only language models trained on an expanding sequence of historical language data.